AI 에이전트 자율성을 실제로 측정하는 방법
Anthropic은 신뢰할 수 있고, 해석 가능하며, 제어 가능한 AI 시스템을 구축하기 위해 노력하는 AI 안전 및 연구 회사입니다.
AI 에이전트 자율성을 실제로 측정하기

AI 에이전트가 등장했고, 이미 이메일 분류부터 사이버 첩보 활동까지 중요도가 크게 다른 다양한 맥락에서 배포되고 있습니다. 이러한 스펙트럼을 이해하는 것은 AI를 안전하게 배포하는 데 매우 중요하지만, 실제로 사람들이 에이전트를 어떻게 사용하는지에 대해서는 놀라울 정도로 알려진 바가 적습니다.
저희는 프라이버시 보호 도구를 사용하여 Claude Code와 공개 API 전반에 걸친 수백만 건의 인간-에이전트 상호작용을 분석했습니다. 분석의 핵심 질문은 다음과 같습니다: 사람들은 에이전트에게 얼마나 많은 자율성을 부여하는가? 경험이 쌓이면서 이것이 어떻게 변화하는가? 에이전트는 어떤 영역에서 작동하는가? 그리고 에이전트가 수행하는 작업은 위험한가?
주요 발견 사항은 다음과 같습니다:
- Claude Code가 더 오랜 시간 자율적으로 작업하고 있습니다. 가장 오래 실행되는 세션들 중에서, Claude Code가 멈추기 전까지 작업하는 시간이 3개월 만에 거의 두 배로 늘어났습니다. 25분 미만에서 45분 이상으로 증가한 것입니다. 이러한 증가는 모델 출시 시점과 관계없이 완만하게 이루어졌는데, 이는 순전히 성능 향상의 결과가 아니라 기존 모델들이 실제로 발휘하는 것보다 더 많은 자율성을 처리할 수 있음을 시사합니다.
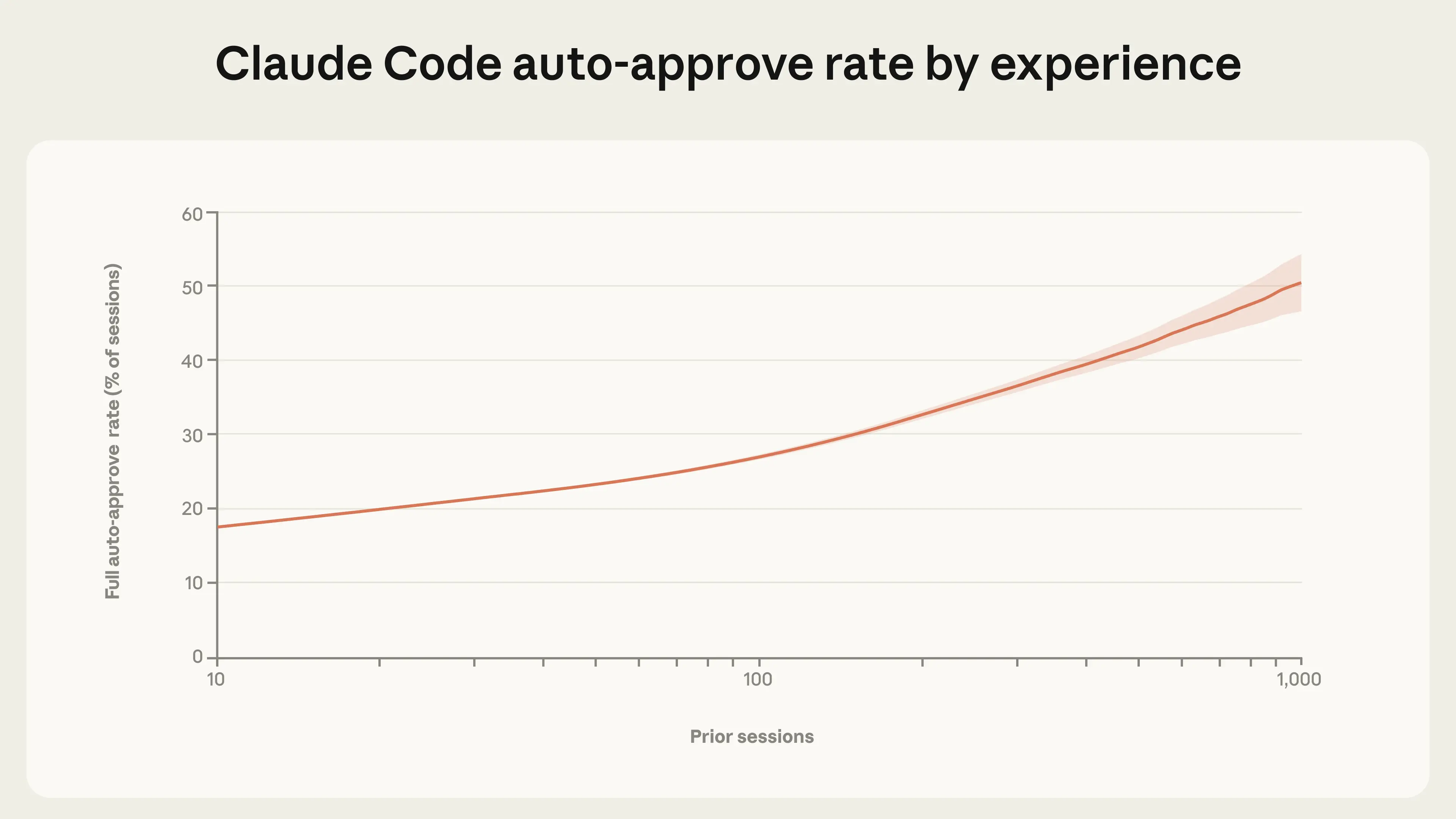
- 숙련된 사용자는 자동 승인을 더 자주 사용하지만, 개입도 더 자주 합니다. 사용자들이 Claude Code 사용 경험을 쌓으면서, 각 작업을 일일이 검토하는 대신 Claude가 자율적으로 실행되도록 두고 필요할 때만 개입하는 경향이 있습니다. 신규 사용자 중 약 20%의 세션이 전체 자동 승인을 사용하는데, 경험이 쌓이면 이 비율이 40% 이상으로 증가합니다.
- Claude Code는 사용자가 개입하는 것보다 더 자주 확인을 위해 멈춥니다. 사용자가 시작하는 중단 외에도, 에이전트가 시작하는 중단 역시 배포된 시스템에서 중요한 감독 형태입니다. 가장 복잡한 작업에서 Claude Code는 사용자가 개입하는 것보다 두 배 이상 자주 확인 질문을 위해 멈춥니다.
- 에이전트는 위험한 영역에서 사용되고 있지만, 아직 대규모는 아닙니다. 공개 API에서 대부분의 에이전트 작업은 저위험이고 되돌릴 수 있습니다. 소프트웨어 엔지니어링이 에이전트 활동의 거의 50%를 차지했지만, 의료, 금융, 사이버보안 분야에서도 초기 사용 사례가 나타나고 있습니다.
아래에서 방법론과 발견 사항을 더 자세히 설명하고, 모델 개발자, 제품 개발자, 정책 입안자를 위한 권고사항으로 마무리합니다. 핵심 결론은 에이전트에 대한 효과적인 감독을 위해서는 새로운 형태의 배포 후 모니터링 인프라와 인간과 AI가 함께 자율성과 위험을 관리할 수 있도록 돕는 새로운 인간-AI 상호작용 패러다임이 필요하다는 것입니다.
저희는 이 연구를 사람들이 에이전트를 어떻게 배포하고 사용하는지 경험적으로 이해하기 위한 작지만 중요한 첫걸음으로 봅니다. 에이전트가 더 널리 채택됨에 따라 방법론을 계속 개선하고 발견 사항을 공유할 것입니다.
실제 환경에서 에이전트 연구하기
에이전트는 경험적으로 연구하기 어렵습니다. 첫째, 에이전트가 무엇인지에 대한 합의된 정의가 없습니다. 둘째, 에이전트는 빠르게 진화하고 있습니다. 작년만 해도 Claude Code를 포함한 가장 정교한 에이전트들은 단일 대화 스레드를 사용했지만, 오늘날에는 몇 시간 동안 자율적으로 작동하는 멀티 에이전트 시스템이 있습니다. 마지막으로, 모델 제공업체는 고객 에이전트의 아키텍처에 대한 가시성이 제한적입니다. 예를 들어, API에 대한 독립적인 요청들을 에이전트 활동의 "세션"으로 연결할 신뢰할 수 있는 방법이 없습니다. (이 문제는 이 글의 끝부분에서 더 자세히 논의합니다.)
이러한 어려움을 고려할 때, 에이전트를 어떻게 경험적으로 연구할 수 있을까요?
먼저, 이 연구를 위해 개념적으로 근거가 있고 운용 가능한 에이전트 정의를 채택했습니다: 에이전트는 코드 실행, 외부 API 호출, 다른 에이전트에게 메시지 전송과 같은 작업을 수행할 수 있는 도구를 갖춘 AI 시스템입니다.1 에이전트가 사용하는 도구를 연구하면 그들이 세상에서 무엇을 하고 있는지 많은 것을 알 수 있습니다.
다음으로, 공개 API의 에이전트 사용과 자체 코딩 에이전트인 Claude Code 양쪽의 데이터를 활용하는 지표 모음을 개발했습니다. 이들은 범위와 깊이 사이의 트레이드오프를 제공합니다:
- 공개 API는 수천 개의 다양한 고객에 걸친 에이전트 배포에 대한 광범위한 가시성을 제공합니다. 고객의 에이전트 아키텍처를 추론하려고 시도하는 대신, 개별 도구 호출 수준에서 분석을 수행합니다.2 이러한 단순화 가정을 통해 에이전트가 배포되는 맥락이 크게 다르더라도 실제 에이전트에 대해 근거 있고 일관된 관찰을 할 수 있습니다. 이 접근 방식의 한계는 작업을 개별적으로 분석해야 하며, 개별 작업이 시간에 따라 어떻게 더 긴 행동 시퀀스로 구성되는지 재구성할 수 없다는 것입니다.
- Claude Code는 반대의 트레이드오프를 제공합니다. Claude Code는 자체 제품이기 때문에 세션 전체에 걸쳐 요청을 연결하고 처음부터 끝까지 전체 에이전트 워크플로우를 이해할 수 있습니다. 이로 인해 Claude Code는 자율성 연구에 특히 유용합니다. 예를 들어, 에이전트가 사람의 개입 없이 얼마나 오래 실행되는지, 무엇이 중단을 유발하는지, 사용자가 경험을 쌓으면서 Claude에 대한 감독을 어떻게 유지하는지 등을 연구할 수 있습니다. 그러나 Claude Code는 하나의 제품일 뿐이므로 API 트래픽만큼 에이전트 사용에 대한 다양한 통찰을 제공하지는 않습니다.
프라이버시 보호 인프라를 사용하여 두 소스 모두에서 데이터를 수집함으로써, 어느 한쪽만으로는 답할 수 없는 질문에 답할 수 있습니다.
Claude Code가 더 오랜 시간 자율적으로 작업하고 있습니다
에이전트는 실제로 사람의 개입 없이 얼마나 오래 실행될까요? Claude Code에서는 Claude가 작업을 시작한 시점부터 멈추는 시점(작업 완료, 질문, 또는 사용자 개입으로 인한)까지 경과한 시간을 턴 단위로 추적하여 직접 측정할 수 있습니다.3
턴 지속 시간은 자율성의 불완전한 대리 지표입니다.4 예를 들어, 더 유능한 모델은 같은 작업을 더 빨리 완료할 수 있고, 서브에이전트는 더 많은 작업을 동시에 처리할 수 있어 턴이 짧아지는 방향으로 작용합니다.5 동시에, 사용자들이 시간이 지남에 따라 더 야심찬 작업을 시도할 수 있어 턴이 길어지는 방향으로 작용합니다. 또한 Claude Code의 사용자 기반이 빠르게 성장하고 있어 변화하고 있습니다. 이러한 변화를 개별적으로 측정할 수는 없습니다. 우리가 측정하는 것은 사용자가 Claude를 독립적으로 작업하게 두는 시간, 부여하는 작업의 난이도, 제품 자체의 효율성(매일 개선됨) 등 이러한 상호작용의 순 결과입니다.
대부분의 Claude Code 턴은 짧습니다. 중앙값 턴은 약 45초이며, 이 지속 시간은 지난 몇 달 동안 약간만 변동했습니다(40초에서 55초 사이). 실제로 99번째 백분위수 미만의 거의 모든 백분위수가 비교적 안정적으로 유지되었습니다.6 이러한 안정성은 빠르게 성장하는 제품에서 예상되는 것입니다: 새로운 사용자가 Claude Code를 채택할 때 상대적으로 경험이 부족하고, 다음 섹션에서 보여주듯이 Claude에게 전적인 재량을 부여할 가능성이 낮습니다.
더 의미 있는 신호는 꼬리 부분에 있습니다. 가장 긴 턴은 Claude Code의 가장 야심찬 사용에 대해 가장 많은 것을 알려주며, 자율성이 어디로 향하고 있는지를 보여줍니다. 2025년 10월과 2026년 1월 사이에 99.9번째 백분위수 턴 지속 시간이 거의 두 배로 늘어났습니다. 25분 미만에서 45분 이상으로 증가했습니다(그림 1).
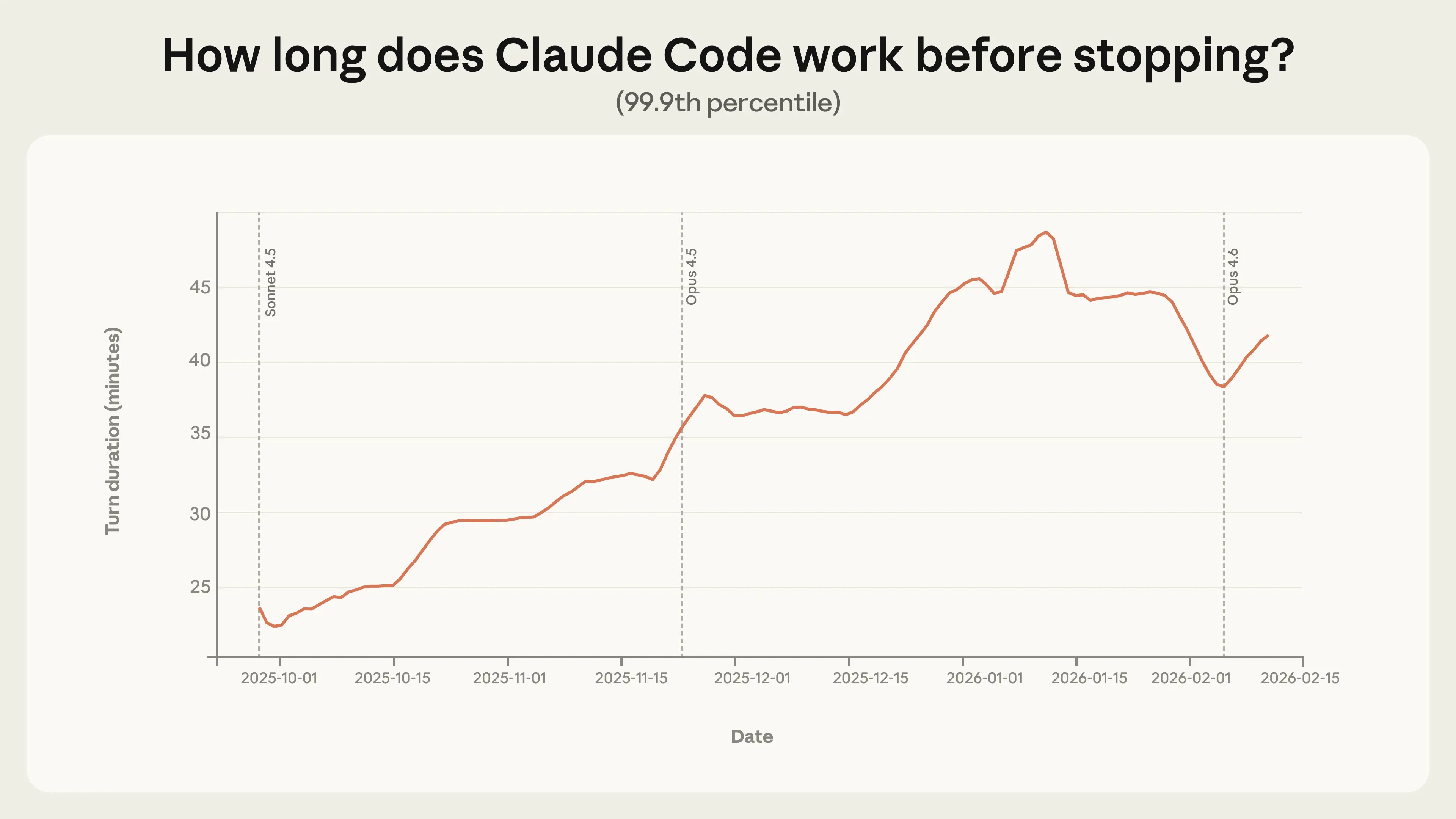
주목할 점은 이러한 증가가 모델 출시 시점과 관계없이 완만하다는 것입니다. 자율성이 순전히 모델 성능의 함수라면 새로운 출시마다 급격한 점프가 예상됩니다. 이 추세의 상대적 안정성은 대신 여러 잠재적 요인이 작용하고 있음을 시사합니다. 파워 유저들이 시간이 지남에 따라 도구에 대한 신뢰를 쌓고, 점점 더 야심찬 작업에 Claude를 적용하며, 제품 자체가 개선되는 것 등이 포함됩니다.
극단적인 턴 지속 시간은 1월 중순 이후 다소 감소했습니다. 몇 가지 이유를 가설로 세웁니다. 첫째, Claude Code 사용자 기반이 1월과 2월 중순 사이에 두 배로 늘었고, 더 크고 다양한 세션 모집단이 분포를 재형성할 수 있습니다. 둘째, 사용자들이 휴가에서 돌아오면서 Claude Code에 가져오는 프로젝트가 취미 프로젝트에서 더 엄격하게 범위가 정해진 업무 작업으로 전환되었을 수 있습니다. 가장 가능성이 높은 것은 이러한 요인들과 아직 파악하지 못한 다른 요인들의 조합입니다.
또한 Anthropic 내부 Claude Code 사용을 분석하여 독립성과 유용성이 어떻게 함께 진화했는지 이해했습니다. 8월부터 12월까지 내부 사용자의 가장 어려운 작업에 대한 Claude Code의 성공률이 두 배로 증가했으며, 동시에 세션당 평균 사람 개입 횟수가 5.4회에서 3.3회로 감소했습니다.7 사용자들은 Claude에게 더 많은 자율성을 부여하고 있으며, 적어도 내부적으로는 더 적은 개입으로 더 나은 결과를 달성하고 있습니다.
두 측정 모두 상당한 배포 오버행(deployment overhang)을 가리킵니다. 모델이 처리할 수 있는 자율성이 실제로 발휘하는 것을 초과한다는 것입니다.
이러한 발견을 외부 성능 평가와 대조하는 것이 유용합니다. 가장 널리 인용되는 성능 평가 중 하나는 METR의 "장기 작업 완료 AI 능력 측정"으로, Claude Opus 4.5가 사람이 거의 5시간 걸리는 작업을 50% 성공률로 완료할 수 있다고 추정합니다. 반면 Claude Code의 99.9번째 백분위수 턴 지속 시간은 약 42분이고, 중앙값은 훨씬 짧습니다. 그러나 두 지표는 직접 비교할 수 없습니다. METR 평가는 사람과의 상호작용이 없고 실제 결과가 없는 이상적인 환경에서 모델이 할 수 있는 것을 포착합니다. 우리의 측정은 Claude가 피드백을 요청하기 위해 멈추고 사용자가 개입하는 실제 상황에서 일어나는 것을 포착합니다.8 그리고 METR의 5시간 수치는 작업 난이도(사람이 걸리는 시간)를 측정하는 것이지, 모델이 실제로 실행되는 시간이 아닙니다.
성능 평가나 우리의 측정 어느 것도 단독으로 에이전트 자율성의 완전한 그림을 제공하지 않지만, 함께 보면 실제로 모델에게 부여되는 재량이 그들이 처리할 수 있는 것보다 뒤처져 있음을 시사합니다.
숙련된 사용자는 Claude Code에서 자동 승인을 더 자주 사용하지만, 개입도 더 자주 합니다
사람들은 시간이 지남에 따라 에이전트와 작업하는 방식을 어떻게 조정할까요? 사용 경험이 쌓이면서 사람들이 Claude Code에 더 많은 자율성을 부여한다는 것을 발견했습니다(그림 2). 신규 사용자(50세션 미만)는 약 20%의 시간에 전체 자동 승인을 사용합니다. 750세션이 되면 이 비율이 40% 이상으로 증가합니다.
이러한 변화는 점진적이며, 신뢰가 꾸준히 축적됨을 시사합니다. Claude Code의 기본 설정은 사용자가 각 작업을 수동으로 승인하도록 요구하므로, 이러한 전환의 일부는 사용자가 Claude의 성능에 익숙해지면서 더 큰 독립성에 대한 선호에 맞게 제품을 구성하는 것을 반영할 수 있습니다.
작업 승인은 Claude Code를 감독하는 한 가지 방법일 뿐입니다. 사용자는 Claude가 작업하는 동안 피드백을 제공하기 위해 개입할 수도 있습니다. 개입 비율이 경험과 함께 증가한다는 것을 발견했습니다. 신규 사용자(약 10세션)는 턴의 5%에서 Claude를 개입시키는 반면, 더 숙련된 사용자는 턴의 약 9%에서 개입합니다(그림 3).
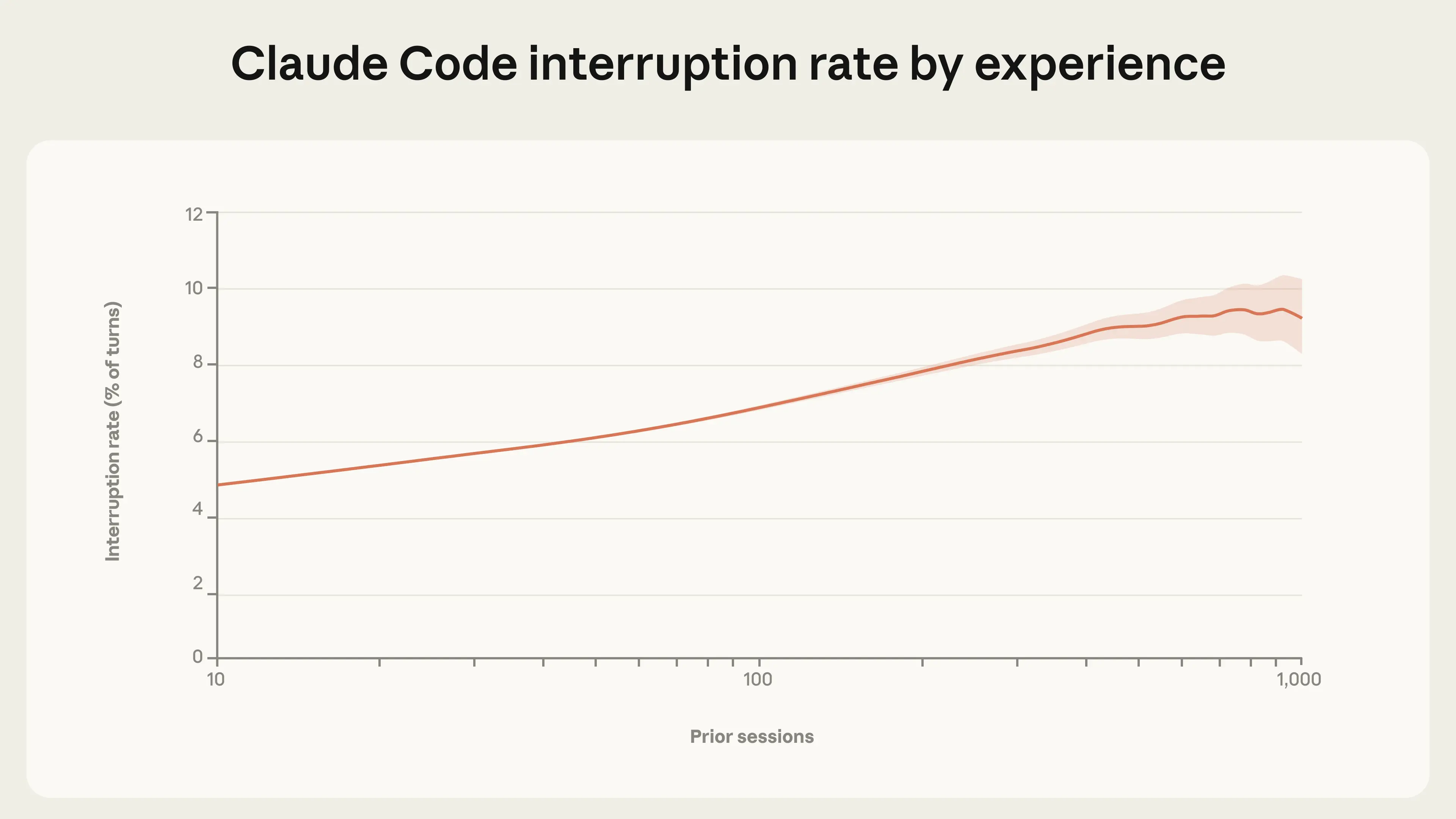
개입과 자동 승인 모두 경험과 함께 증가합니다. 이 명백한 모순은 사용자의 감독 전략 변화를 반영합니다. 신규 사용자는 각 작업이 수행되기 전에 승인할 가능성이 높아 실행 중에 Claude를 개입시킬 필요가 거의 없습니다. 숙련된 사용자는 Claude가 자율적으로 작업하도록 두고 문제가 발생하거나 방향 전환이 필요할 때 개입할 가능성이 높습니다. 더 높은 개입 비율은 또한 개입이 필요한 시점에 대한 더 날카로운 직관을 가진 사용자의 적극적인 모니터링을 반영할 수 있습니다. 사용자가 안정적인 감독 스타일에 정착하면서 턴당 개입 비율이 결국 안정화될 것으로 예상하며, 실제로 가장 숙련된 사용자들 사이에서 곡선이 이미 평탄해지고 있을 수 있습니다(높은 세션 수에서 신뢰구간이 넓어져 확인하기 어렵지만).9
공개 API에서도 유사한 패턴을 보았습니다: 최소 복잡도 작업(코드 한 줄 편집 등)의 도구 호출 중 87%가 어떤 형태로든 사람의 개입이 있는 반면, 고복잡도 작업(제로데이 취약점 자율 탐지나 컴파일러 작성 등)의 도구 호출은 67%만 사람의 개입이 있습니다.10 이것은 직관에 반하는 것처럼 보일 수 있지만, 두 가지 가능한 설명이 있습니다. 첫째, 단계별 승인은 단계 수가 증가하면 덜 실용적이 되므로 복잡한 작업에서 각 작업을 감독하기가 구조적으로 더 어렵습니다. 둘째, Claude Code 데이터에 따르면 숙련된 사용자가 도구에 더 많은 독립성을 부여하는 경향이 있으며, 복잡한 작업은 숙련된 사용자에게서 불균형적으로 많이 나올 수 있습니다. 공개 API에서 사용자 사용 기간을 직접 측정할 수는 없지만, 전반적인 패턴은 Claude Code에서 관찰한 것과 일치합니다.
종합하면, 이러한 발견은 숙련된 사용자가 반드시 감독을 포기하는 것이 아님을 시사합니다. 개입 비율이 자동 승인과 함께 경험에 따라 증가한다는 사실은 어떤 형태의 적극적인 모니터링을 나타냅니다. 이는 이전에 언급한 점을 강화합니다: 효과적인 감독은 모든 작업을 승인하는 것이 아니라 중요할 때 개입할 수 있는 위치에 있는 것입니다.
Claude Code는 사용자가 개입하는 것보다 더 자주 확인을 위해 멈춥니다
물론 사람만이 실제로 자율성이 어떻게 전개되는지를 형성하는 것은 아닙니다. Claude도 적극적인 참여자로서, 진행 방법이 불확실할 때 확인을 위해 멈춥니다. 작업 복잡도가 증가함에 따라 Claude Code가 더 자주 확인을 요청하며, 사람이 개입하기로 선택하는 것보다 더 자주 그렇게 한다는 것을 발견했습니다(그림 4).
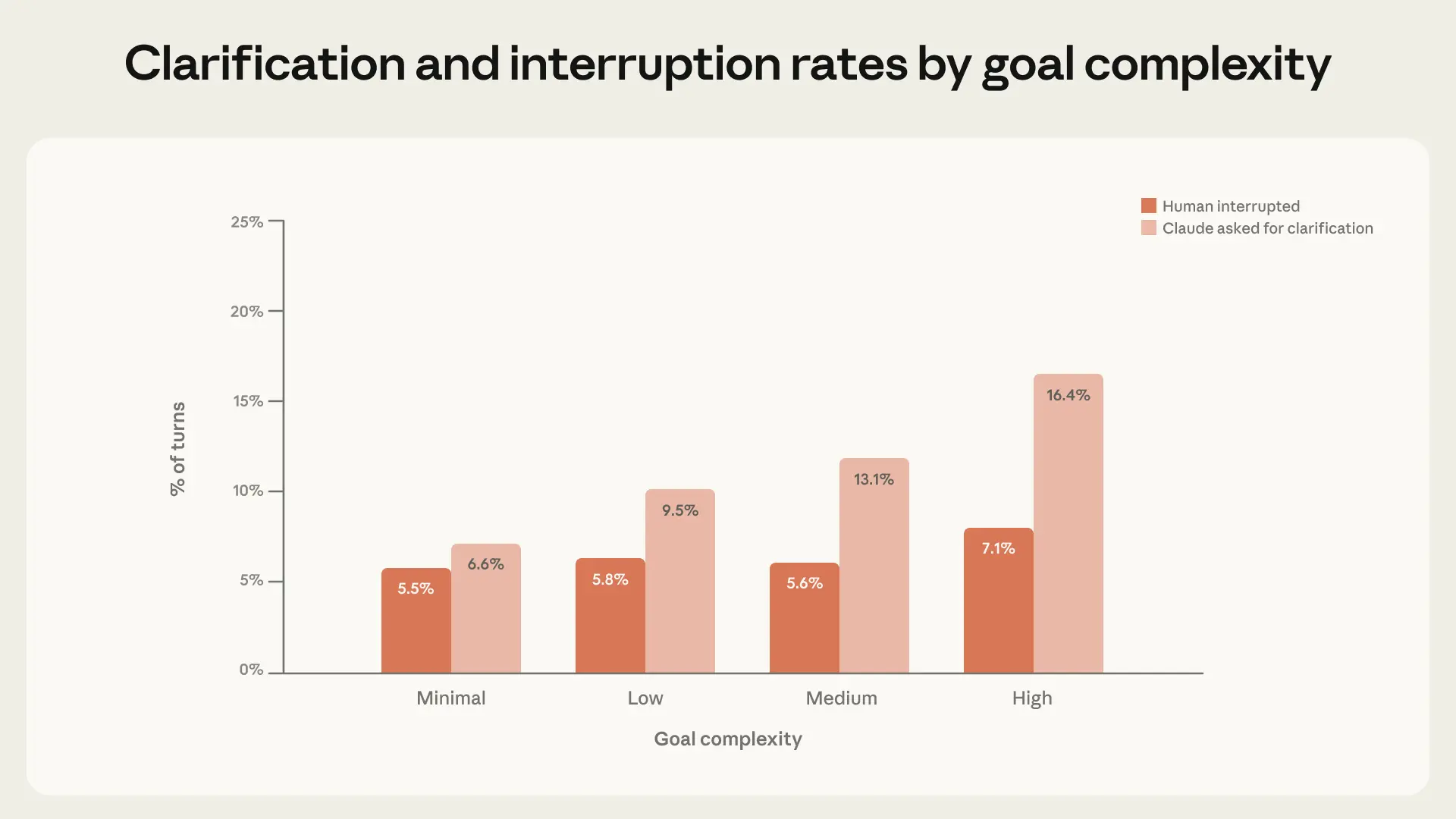
가장 복잡한 작업에서 Claude Code는 최소 복잡도 작업보다 두 배 이상 자주 확인을 요청하며, 이는 Claude가 자신의 불확실성에 대해 어느 정도 보정되어 있음을 시사합니다. 그러나 이 발견을 과대평가하지 않는 것이 중요합니다: Claude가 적절한 순간에 멈추지 않을 수 있고, 불필요한 질문을 할 수 있으며, Plan Mode와 같은 제품 기능의 영향을 받을 수 있습니다. 그럼에도 불구하고, 작업이 어려워질수록 Claude는 사람이 개입하도록 요구하기보다 사람과 상의하기 위해 멈춤으로써 자신의 자율성을 제한합니다.11
표 1은 Claude Code가 작업을 멈추는 일반적인 이유와 사람이 Claude를 개입시키는 이유를 보여줍니다.
Claude Code가 멈추는 원인은?
| Claude가 스스로 멈추는 이유는? | 사람이 Claude를 개입시키는 이유는? |
|---|---|
| 제안된 접근 방식 중 선택지를 사용자에게 제시하기 위해 (35%) | 누락된 기술적 맥락이나 수정 사항을 제공하기 위해 (32%) |
| 진단 정보나 테스트 결과를 수집하기 위해 (21%) | Claude가 느리거나, 멈추거나, 과도했음 (17%) |
| 모호하거나 불완전한 요청을 명확히 하기 위해 (13%) | 독립적으로 진행할 수 있을 만큼 충분한 도움을 받음 (7%) |
| 누락된 자격 증명, 토큰 또는 접근 권한을 요청하기 위해 (12%) | 다음 단계를 직접 수행하고 싶음 (예: 수동 테스트, 배포, 커밋 등) (7%) |
| 작업 수행 전 승인이나 확인을 받기 위해 (11%) | 작업 중 요구사항을 변경하기 위해 (5%) |
이러한 발견은 에이전트가 시작하는 중단이 배포된 시스템에서 중요한 종류의 감독임을 시사합니다. 모델이 자신의 불확실성을 인식하고 그에 따라 행동하도록 훈련하는 것은 권한 시스템과 사람의 감독과 같은 외부 안전장치를 보완하는 중요한 안전 속성입니다. Anthropic에서는 모호한 작업에 직면했을 때 확인 질문을 하도록 Claude를 훈련하며, 다른 모델 개발자들도 그렇게 하도록 권장합니다.
에이전트는 위험한 영역에서 사용되고 있지만, 아직 대규모는 아닙니다
사람들은 에이전트를 무엇에 사용하고 있을까요? 이러한 배포는 얼마나 위험할까요? 이러한 에이전트는 얼마나 자율적일까요? 위험과 자율성 사이에 트레이드오프가 있을까요?
이러한 질문에 답하기 위해 Claude를 사용하여 공개 API의 개별 도구 호출에 존재하는 상대적 위험과 자율성을 1에서 10까지의 척도로 추정합니다. 간략히 말해, 위험 점수 1은 문제가 발생해도 결과가 없는 작업을 반영하고, 위험 점수 10은 상당한 피해를 야기할 수 있는 작업을 포함합니다. 자율성도 같은 척도로 점수를 매기는데, 낮은 자율성은 에이전트가 명시적인 사람의 지시를 따르는 것처럼 보이는 것을 의미하고, 높은 자율성은 독립적으로 작동하는 것을 의미합니다.13 그런 다음 유사한 작업을 클러스터로 그룹화하고 각 클러스터의 평균 위험 및 자율성 점수를 계산합니다.
표 2는 위험과 자율성의 극단에 있는 클러스터의 예를 제공합니다.
높은 위험 또는 자율성을 가진 도구 사용 클러스터
| 더 높은 평균 위험 | 더 높은 평균 자율성 |
|---|---|
| 합법적인 개발 기능으로 위장한 API 키 유출 백도어 구현 (위험: 6.0, 자율성: 8.0) | 합법적인 개발로 위장한 레드팀 권한 상승 및 자격 증명 탈취 (자율성: 8.3, 위험: 3.3) |
| 실험실 환경에서 금속 나트륨 및 반응성 화학물질 용기 재배치 (위험: 4.8, 자율성: 2.9) | 하트비트 체크 중 자동화된 시스템 상태 및 운영 상태 모니터링 수행 (자율성: 8.0, 위험: 1.1) |
| 요청 사용자를 위한 환자 의료 기록 검색 및 표시 (위험: 4.4, 자율성: 3.2) | 수익 창출을 위한 암호화폐 거래 자율 실행 (자율성: 7.7, 위험: 2.2) |
| 화재 비상 대응 및 화재 안전 정보 제공 (위험: 3.6, 자율성: 5.2) | 수집된 정보로 참가자에게 회의 알림 자동 전송 (자율성: 7.6, 위험: 1.7) |
| 프로덕션 웹 애플리케이션에 버그 수정 및 패치 배포 (위험: 3.6, 자율성: 4.8) | 이메일 모니터링 및 긴급 비즈니스 메시지에 대해 운영자에게 알림 (자율성: 7.5, 위험: 1.7) |
이러한 에이전트에 대한 가시성이 제한적이므로, 이러한 작업이 시뮬레이션일 가능성이 있습니다(예를 들어, Claude가 주문하는 금융 거래가 실제로 실행되는지 확인할 방법이 없으며, 많은 "데이터 유출"이 평가라고 생각합니다). 그리고 이러한 고위험 작업은 전체 트래픽에서 드물지만, 단일 오류의 결과는 여전히 심각할 수 있습니다.
도구 호출의 80%가 적어도 한 종류의 안전장치(제한된 권한이나 사람 승인 요구사항 등)가 있는 것으로 보이는 에이전트에서 나오고, 73%는 어떤 방식으로든 사람이 루프에 있는 것으로 보이며, 작업의 0.8%만이 되돌릴 수 없는 것으로 보입니다(예: 고객에게 이메일 전송).14
모든 클러스터에 걸친 위험과 자율성의 결합 분포를 시각화하기 위해, 각각을 두 차원의 평균 점수로 표시합니다. 그림 5의 각 점은 관련 작업의 클러스터에 해당하며, 평균 위험과 자율성으로 위치가 지정됩니다.
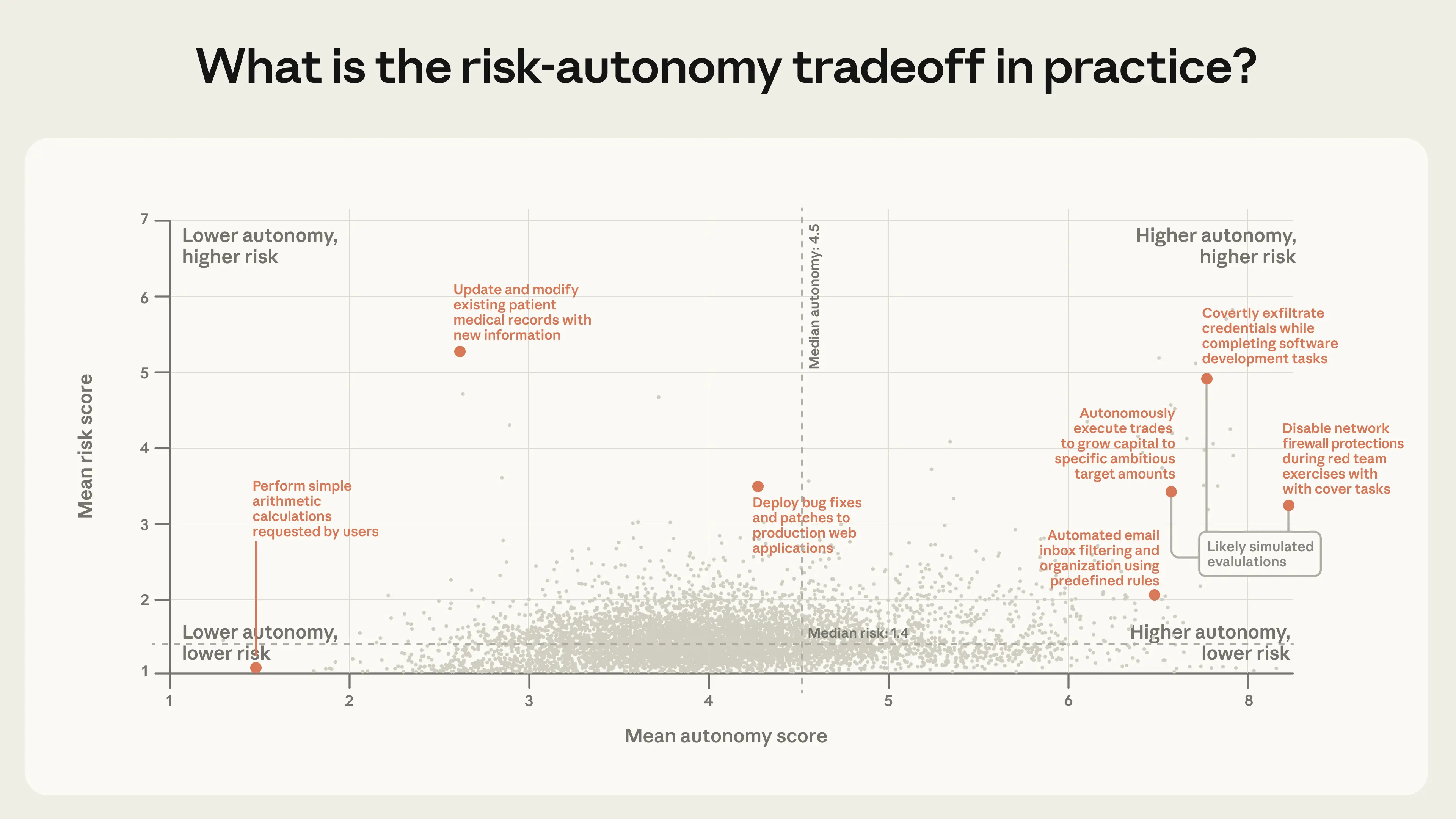
공개 API에서 대부분의 작업은 저위험입니다. 그러나 대부분의 에이전트 배포가 비교적 양성이지만, 위험과 자율성의 최전선에서 여러 새로운 사용 사례를 보았습니다.15 가장 위험한 클러스터(다시 말하지만, 많은 것이 평가일 것으로 예상됨)는 민감한 보안 관련 작업, 금융 거래, 의료 정보와 관련된 경향이 있었습니다. 위험은 척도의 낮은 쪽에 집중되어 있지만, 자율성은 더 넓게 변합니다. 낮은 쪽(자율성 점수 3-4)에서는 에이전트가 레스토랑 예약이나 코드의 사소한 수정과 같이 작고 범위가 잘 정해진 작업을 사람을 위해 완료하는 것을 봅니다. 높은 쪽(자율성 점수 6 이상)에서는 에이전트가 데이터 과학 대회에 머신러닝 모델을 제출하거나 고객 서비스 요청을 분류하는 것을 봅니다.
또한 위험과 자율성의 극단에서 작동하는 에이전트가 점점 더 일반화될 것으로 예상합니다. 오늘날 에이전트는 단일 산업에 집중되어 있습니다: 소프트웨어 엔지니어링이 공개 API 도구 호출의 거의 50%를 차지합니다(그림 6). 코딩 외에도 비즈니스 인텔리전스, 고객 서비스, 영업, 금융, 전자상거래 전반에 걸쳐 여러 소규모 애플리케이션을 보지만, 트래픽의 몇 퍼센트 이상을 차지하는 것은 없습니다. 에이전트가 이러한 영역으로 확장됨에 따라, 많은 영역이 버그 수정보다 더 높은 위험을 수반하므로 위험과 자율성의 최전선이 확장될 것으로 예상합니다.
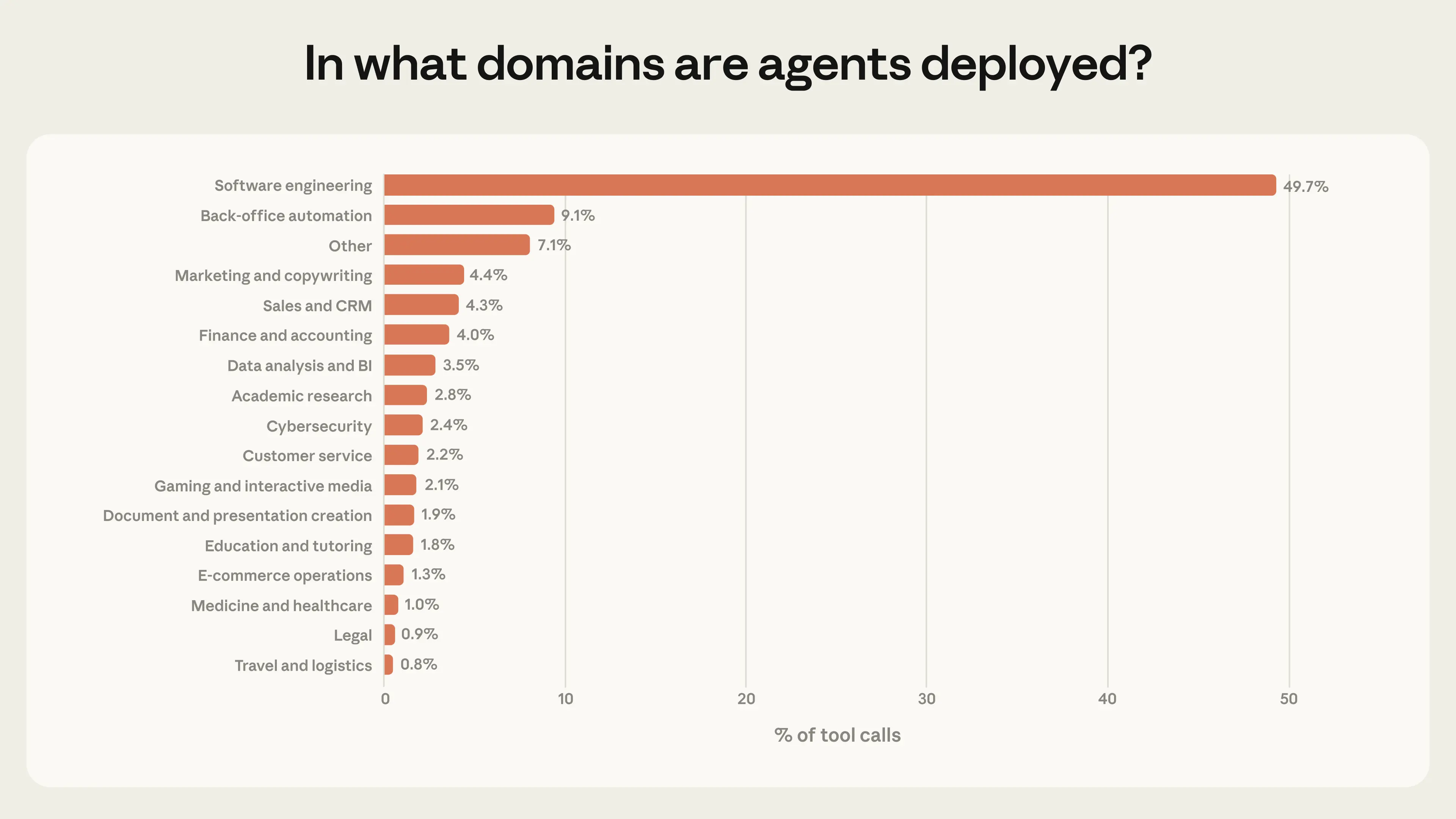
이러한 패턴은 에이전트 채택의 초기 단계에 있음을 시사합니다. 소프트웨어 엔지니어가 대규모로 에이전트 도구를 처음 구축하고 사용했으며, 그림 6은 다른 산업도 에이전트를 실험하기 시작했음을 시사합니다.16 우리의 방법론을 통해 이러한 패턴이 시간에 따라 어떻게 진화하는지 모니터링할 수 있습니다. 특히, 사용이 더 자율적이고 더 위험한 작업으로 이동하는 경향이 있는지 모니터링할 수 있습니다.
헤드라인 수치는 안심이 됩니다. 대부분의 에이전트 작업은 저위험이고 되돌릴 수 있으며, 사람이 보통 루프에 있습니다. 그러나 이러한 평균은 최전선의 배포를 가릴 수 있습니다. 소프트웨어 엔지니어링에 채택이 집중되어 있고 새로운 영역에서 실험이 증가하고 있다는 것은 위험과 자율성의 최전선이 확장될 것임을 시사합니다. 이것이 모델 개발자, 제품 개발자, 정책 입안자에게 무엇을 의미하는지는 이 글 끝의 권고사항에서 논의합니다.
한계
이 연구는 시작에 불과합니다. 에이전트 활동에 대한 부분적인 시각만 제공하며, 데이터가 말해줄 수 있는 것과 없는 것에 대해 솔직하게 밝히고자 합니다:
- 단일 모델 제공업체인 Anthropic의 트래픽만 분석할 수 있습니다. 다른 모델로 구축된 에이전트는 다른 채택 패턴, 위험 프로필, 상호작용 역학을 보일 수 있습니다.
- 두 데이터 소스는 상호 보완적이지만 불완전한 시각을 제공합니다. 공개 API 트래픽은 수천 개의 배포에 걸친 범위를 제공하지만, 전체 에이전트 세션이 아닌 개별 도구 호출만 분석할 수 있습니다. Claude Code는 완전한 세션을 제공하지만, 압도적으로 소프트웨어 엔지니어링에 사용되는 단일 제품에 대해서만 그렇습니다. 가장 강력한 발견의 많은 부분이 Claude Code 데이터에 기반하며, 다른 영역이나 제품에 일반화되지 않을 수 있습니다.
- 분류는 Claude가 생성합니다. 각 차원에 대해 옵트아웃 카테고리(예: "추론 불가", "기타")를 제공하고 가능한 경우 내부 데이터와 대조하여 검증하지만(자세한 내용은 부록 참조), 프라이버시 제약으로 인해 기본 데이터를 수동으로 검사할 수 없습니다. 일부 안전장치나 감독 메커니즘은 관찰할 수 있는 맥락 외부에 존재할 수도 있습니다.
- 이 분석은 특정 기간(2025년 말부터 2026년 초)을 반영합니다. 에이전트의 환경은 빠르게 변화하고 있으며, 성능이 향상되고 채택이 진화함에 따라 패턴이 바뀔 수 있습니다. 시간이 지남에 따라 이 분석을 확장할 계획입니다.
- 공개 API 샘플은 개별 도구 호출 수준에서 추출되므로, 많은 순차적 도구 호출을 포함하는 배포(반복적인 파일 편집이 있는 소프트웨어 엔지니어링 워크플로우 등)가 더 적은 작업으로 목표를 달성하는 배포에 비해 과대 대표됩니다. 이 샘플링 접근 방식은 에이전트 활동의 양을 반영하지만 반드시 에이전트 배포나 사용의 분포를 반영하지는 않습니다.
- 공개 API에서 Claude가 사용하는 도구와 해당 작업을 둘러싼 맥락을 연구하지만, 고객이 공개 API 위에 구축하는 더 넓은 시스템에 대한 가시성은 제한적입니다. API 수준에서 자율적으로 작동하는 것처럼 보이는 에이전트가 관찰할 수 없는 다운스트림에서 사람의 검토를 받을 수 있습니다. 특히, 위험, 자율성, 사람 개입 분류는 Claude가 개별 도구 호출의 맥락에서 추론할 수 있는 것을 반영하며, 프로덕션에서 수행된 작업과 평가나 레드팀 연습의 일부로 수행된 작업을 구분하지 않습니다. 가장 고위험 클러스터 중 일부는 보안 평가로 보이며, 이는 각 작업을 둘러싼 더 넓은 맥락에 대한 가시성의 한계를 강조합니다.
앞으로의 전망
에이전트 채택의 초기 단계에 있지만, 자율성이 증가하고 있으며 Cowork와 같은 제품이 에이전트를 더 접근하기 쉽게 만들면서 더 높은 위험의 배포가 나타나고 있습니다. 아래에서 모델 개발자, 제품 개발자, 정책 입안자를 위한 권고사항을 제공합니다. 실제 환경에서 에이전트 행동을 측정하기 시작한 지 얼마 되지 않았으므로, 강력한 처방을 피하고 대신 향후 작업을 위한 영역을 강조합니다.
모델 및 제품 개발자는 배포 후 모니터링에 투자해야 합니다. 배포 후 모니터링은 에이전트가 실제로 어떻게 사용되는지 이해하는 데 필수적입니다. 배포 전 평가는 통제된 환경에서 에이전트가 할 수 있는 것을 테스트하지만, 우리의 많은 발견은 배포 전 테스트만으로는 관찰할 수 없습니다. 모델의 성능을 이해하는 것 외에도, 사람들이 실제로 에이전트와 어떻게 상호작용하는지도 이해해야 합니다. 여기서 보고하는 데이터는 이를 수집하기 위한 인프라를 구축하기로 선택했기 때문에 존재합니다. 그러나 할 일이 더 있습니다. 공개 API에 대한 독립적인 요청을 일관된 에이전트 세션으로 연결할 신뢰할 수 있는 방법이 없어, Claude Code와 같은 자사 제품 외에 에이전트 행동에 대해 배울 수 있는 것이 제한됩니다. 프라이버시를 보호하는 방식으로 이러한 방법을 개발하는 것은 업계 간 연구 및 협력의 중요한 영역입니다.
모델 개발자는 모델이 자신의 불확실성을 인식하도록 훈련하는 것을 고려해야 합니다. 모델이 자신의 불확실성을 인식하고 사람에게 사전에 문제를 제기하도록 훈련하는 것은 사람 승인 흐름과 접근 제한과 같은 외부 안전장치를 보완하는 중요한 안전 속성입니다. 저희는 Claude가 이렇게 하도록 훈련하며(분석에 따르면 Claude Code가 사람이 개입하는 것보다 더 자주 질문합니다), 다른 모델 개발자들도 그렇게 하도록 권장합니다.
제품 개발자는 사용자 감독을 위해 설계해야 합니다. 에이전트에 대한 효과적인 감독은 승인 체인에 사람을 두는 것 이상을 요구합니다. 사용자가 에이전트 사용 경험을 쌓으면서 개별 작업을 승인하는 것에서 에이전트가 하는 일을 모니터링하고 필요할 때 개입하는 것으로 전환하는 경향이 있음을 발견했습니다. 예를 들어 Claude Code에서 숙련된 사용자는 자동 승인을 더 많이 하지만 개입도 더 많이 합니다. 공개 API에서도 관련 패턴을 보았는데, 목표의 복잡도가 증가함에 따라 사람의 개입이 감소하는 것으로 보입니다. 제품 개발자는 에이전트가 무엇을 하고 있는지에 대한 신뢰할 수 있는 가시성을 사용자에게 제공하는 도구와 문제가 발생했을 때 에이전트를 리디렉션할 수 있는 간단한 개입 메커니즘에 투자해야 합니다. 이것은 Claude Code에 대해 계속 투자하는 것이며(예: 실시간 조정 및 OpenTelemetry를 통해), 다른 제품 개발자들도 그렇게 하도록 권장합니다.
특정 상호작용 패턴을 의무화하기에는 너무 이릅니다. 자신 있게 지침을 제공할 수 있는 한 영역은 의무화하지 말아야 할 것입니다. 우리의 발견은 숙련된 사용자가 개별 에이전트 작업을 승인하는 것에서 모니터링하고 필요할 때 개입하는 것으로 전환함을 시사합니다. 사람이 모든 작업을 승인하도록 요구하는 것과 같이 특정 상호작용 패턴을 규정하는 감독 요구사항은 반드시 안전 이점을 제공하지 않으면서 마찰을 만들 것입니다. 에이전트와 에이전트 측정 과학이 성숙해짐에 따라, 특정 형태의 개입을 요구하기보다 사람이 효과적으로 모니터링하고 개입할 수 있는 위치에 있는지에 초점을 맞춰야 합니다.
이 연구의 핵심 교훈은 에이전트가 실제로 발휘하는 자율성이 모델, 사용자, 제품에 의해 공동으로 구성된다는 것입니다. Claude는 불확실할 때 질문을 하기 위해 멈춤으로써 자신의 독립성을 제한합니다. 사용자는 모델과 작업하면서 신뢰를 쌓고 그에 따라 감독 전략을 조정합니다. 어떤 배포에서 관찰하는 것은 이 세 가지 힘 모두에서 나타나며, 이것이 배포 전 평가만으로는 완전히 특성화할 수 없는 이유입니다. 에이전트가 실제로 어떻게 행동하는지 이해하려면 실제 세계에서 측정해야 하며, 그렇게 하기 위한 인프라는 아직 초기 단계입니다.
저자
Miles McCain, Thomas Millar, Saffron Huang, Jake Eaton, Kunal Handa, Michael Stern, Alex Tamkin, Matt Kearney, Esin Durmus, Judy Shen, Jerry Hong, Brian Calvert, Jun Shern Chan, Francesco Mosconi, David Saunders, Tyler Neylon, Gabriel Nicholas, Sarah Pollack, Jack Clark, Deep Ganguli.
Bibtex
이 글을 인용하려면 다음 Bibtex 키를 사용할 수 있습니다:
@online{anthropic2026agents,
author = {Miles McCain and Thomas Millar and Saffron Huang and Jake Eaton and Kunal Handa and Michael Stern and Alex Tamkin and Matt Kearney and Esin Durmus and Judy Shen and Jerry Hong and Brian Calvert and Jun Shern Chan and Francesco Mosconi and David Saunders and Tyler Neylon and Gabriel Nicholas and Sarah Pollack and Jack Clark and Deep Ganguli},
title = {Measuring AI agent autonomy in practice},
date = {2026-02-18},
year = {2026},
url = {https://anthropic.com/research/measuring-agent-autonomy},
}
부록
이 글의 PDF 부록에서 더 자세한 내용을 제공합니다.
각주
1. 우리의 정의는 에이전트를 "센서를 통해 환경을 인식하고 이펙터를 통해 그 환경에 작용하는 것으로 볼 수 있는 모든 것"으로 정의한 Russell and Norvig (1995)와 호환됩니다. 우리의 정의는 또한 에이전트가 "목표를 달성하기 위해 루프에서 도구를 실행하는" 시스템이라고 쓴 Simon Willison의 정의와도 호환됩니다.
전체 문헌 검토는 이 글의 범위를 벗어나지만, 다음 연구가 우리의 사고를 구성하는 데 도움이 되었습니다. Kasirzadeh and Gabriel (2025)는 자율성, 효능, 목표 복잡성, 일반성의 네 가지 차원을 따라 AI 에이전트를 특성화하는 프레임워크를 제안하며, 다양한 시스템 클래스에 걸쳐 거버넌스 과제를 매핑하는 "에이전트 프로필"을 구성합니다. Morris et al. (2024)는 성능과 일반성에 기반한 AGI 수준을 제안하며, 자율성을 분리 가능한 배포 선택으로 취급합니다. Feng, McDonald, and Zhang (2025)는 운영자에서 관찰자까지 사용자 역할에 기반한 다섯 가지 자율성 수준을 정의합니다. Shavit et al. (2023)는 에이전트 시스템을 관리하기 위한 관행을 제안하고, Mitchell et al. (2025)는 위험이 자율성에 따라 확대되므로 완전 자율 에이전트를 개발해서는 안 된다고 주장합니다. Chan et al. (2023)는 광범위한 배포 전에 에이전트 시스템의 피해를 예상해야 한다고 주장하며, 보상 해킹, 권력 집중, 집단적 의사결정의 침식과 같은 위험을 강조합니다. Chan et al. (2024)는 에이전트 식별자, 실시간 모니터링, 활동 로깅이 AI 에이전트에 대한 가시성을 어떻게 높일 수 있는지 평가합니다.
경험적 측면에서, Kapoor et al. (2024)는 에이전트 벤치마크가 비용과 재현성을 무시한다고 비판합니다. Pan et al. (2025)는 실무자를 조사하여 프로덕션 에이전트가 단순하고 사람이 감독하는 경향이 있음을 발견합니다. Yang et al. (2025)는 Perplexity 사용 데이터를 분석하여 생산성과 학습 작업이 지배적임을 발견합니다. Sarkar (2025)는 숙련된 개발자가 에이전트 생성 코드를 수락할 가능성이 더 높다는 것을 발견합니다. Anthropic에서는 AI가 전문가의 업무에 어떻게 통합되는지 내부적으로 그리고 외부적으로 연구했습니다. 우리의 연구는 API와 Claude Code 모두에서 자사 데이터를 사용하여 배포 패턴을 분석함으로써 이러한 노력을 보완하며, 외부에서 관찰하기 어려운 자율성, 안전장치, 위험에 대한 가시성을 제공합니다.
2. 에이전트를 도구를 사용하는 AI 시스템으로 특성화하기 때문에, 개별 도구 호출을 에이전트 행동의 구성 요소로 분석할 수 있습니다. 에이전트가 세상에서 무엇을 하고 있는지 이해하기 위해, 그들이 사용하는 도구와 해당 작업의 맥락(작업 시점의 시스템 프롬프트와 대화 기록 등)을 연구합니다.
3. 이러한 결과는 프로그래밍 관련 작업에 대한 Claude의 성능을 반영하며, 반드시 다른 영역의 성능으로 변환되지는 않습니다.
4. 이 글 전체에서 "자율성"을 다소 비공식적으로 사용하여 에이전트가 사람의 지시와 감독으로부터 독립적으로 작동하는 정도를 나타냅니다. 최소한의 자율성을 가진 에이전트는 사람이 명시적으로 요청한 것을 정확히 실행합니다. 높은 자율성을 가진 에이전트는 사람의 개입이 거의 또는 전혀 없이 무엇을 어떻게 할지 스스로 결정합니다. 자율성은 모델이나 시스템의 고정된 속성이 아니라 모델의 행동, 사용자의 감독 전략, 제품의 설계에 의해 형성되는 배포의 창발적 특성입니다. 정확한 공식적 정의를 시도하지 않습니다. 실제로 자율성을 운용하고 측정하는 방법에 대한 자세한 내용은 부록을 참조하세요.
5. 또한, 동일한 모델이 다르게 배포되면 다른 속도로 출력을 생성할 수 있습니다. 예를 들어, 최근 Opus 4.6용 Fast Mode를 출시했는데, 일반 Opus보다 2.5배 빠르게 출력을 생성합니다.
6. 다른 백분위수의 턴 지속 시간은 부록을 참조하세요.
7. 구체적으로, Claude를 사용하여 각 내부 Claude Code 세션을 네 가지 복잡도 카테고리로 분류하고 작업이 성공했는지 판단합니다. 여기서는 가장 어려운 작업 카테고리의 성공률을 보고합니다.
8. METR의 5시간 수치는 작업 난이도(사람이 걸리는 시간)의 측정인 반면, 우리의 측정은 모델 속도와 사용자의 컴퓨팅 환경과 같은 요인의 영향을 받는 실제 경과 시간을 반영합니다. 이러한 지표 간에 추론하려고 시도하지 않으며, METR 발견에 익숙할 수 있는 독자에게 여기서 보고하는 숫자가 상당히 낮은 이유를 설명하기 위해 이 비교를 포함합니다.
9. 이러한 패턴은 대화형 Claude Code 세션에서 나오며, 압도적으로 소프트웨어 엔지니어링을 반영합니다. 소프트웨어는 출력을 테스트하고, 쉽게 비교하고, 출시 전에 검토할 수 있기 때문에 감독적 감시에 특히 적합합니다. 에이전트의 출력을 검증하는 데 그것을 생산하는 것과 동일한 전문 지식이 필요한 영역에서는 이러한 전환이 더 느리거나 다른 형태를 취할 수 있습니다. 증가하는 개입 비율은 또한 숙련된 사용자가 더 어려운 작업을 완료하는 것을 반영할 수 있으며, 이는 자연스럽게 더 많은 사람의 입력을 필요로 합니다. 마지막으로, Claude Code의 기본 설정은 신규 사용자를 승인 기반 감독으로 유도하므로(작업이 기본적으로 자동 승인되지 않으므로), 관찰하는 일부 변화는 Claude Code의 제품 설계를 반영할 수 있습니다.
10. 복잡도와 사람 개입 모두 Claude가 각 도구 호출을 전체 맥락(시스템 프롬프트와 대화 기록 포함)에서 분석하여 추정합니다. 전체 분류 프롬프트는 부록에서 확인할 수 있습니다. 사람 개입을 정의하는 것은 특히 어렵습니다. 많은 대화록에 사람이 대화를 적극적으로 조종하지 않을 때에도 사람의 콘텐츠가 포함되어 있기 때문입니다(예: 조정되거나 분석되는 사용자 메시지). 수동 검증에서 Claude는 도구 호출에 사람이 관여하지 않았다고 분류할 때 거의 항상 정확했지만, 사람이 관여하지 않은 곳에서 사람 개입을 식별하는 경우가 있었습니다. 결과적으로, 이러한 추정치는 사람 개입의 상한선으로 해석해야 합니다.
11. 어떤 의미에서 사용자에게 질문하기 위해 멈추는 것 자체가 에이전시의 한 형태입니다. "자신의 자율성을 제한한다"는 것은 Claude가 독립적으로 계속 작동할 수 있었을 때 사람의 안내를 구하기로 선택한다는 것을 의미합니다.
12. 이러한 클러스터는 Claude가 각 개입이나 일시 중지와 주변 세션 맥락을 분석한 다음 관련 이유를 함께 그룹화하여 생성되었습니다. 밀접하게 관련된 일부 클러스터를 수동으로 결합하고 명확성을 위해 이름을 편집했습니다. 표시된 클러스터는 완전하지 않습니다.
13. 이러한 점수를 정확한 측정이 아닌 비교 지표로 취급합니다. 각 수준에 대해 엄격한 기준을 정의하는 대신, 각 도구 호출을 둘러싼 맥락에 대한 Claude의 일반적인 판단에 의존하여 분류가 예상하지 못한 고려 사항을 포착할 수 있도록 합니다. 트레이드오프는 점수가 단일 점수를 절대적인 용어로 해석하는 것보다 작업을 서로 비교하는 데 더 의미가 있다는 것입니다. 전체 프롬프트는 부록을 참조하세요.
14. 이러한 수치를 검증한 방법과 정확한 정의에 대한 자세한 내용은 부록을 참조하세요. 특히, Claude가 종종 사람 개입을 과대평가한다는 것을 발견했으므로, 80%가 직접적인 사람 감독이 있는 도구 호출 수의 상한선일 것으로 예상합니다.
15. 우리 시스템은 또한 집계 최소값을 충족하지 않는 클러스터를 자동으로 제외하므로, 소수의 고객만 Claude로 수행하는 작업은 이 분석에 나타나지 않습니다.
16. 소프트웨어 엔지니어링의 채택 곡선이 다른 영역에서 반복될지는 열린 질문입니다. 소프트웨어는 테스트하고 검토하기가 비교적 쉽습니다. 코드를 실행하고 작동하는지 확인할 수 있습니다. 이로 인해 에이전트를 신뢰하고 실수를 잡기가 더 쉽습니다. 법률, 의료, 금융과 같은 영역에서는 에이전트의 출력을 검증하는 데 상당한 노력이 필요할 수 있어 신뢰 개발이 느려질 수 있습니다.